Why is Computer Vision Hard?
Computer Vision has come a long way, but why is it so challenging? We dive into this question to see how far Computer Vision has come and what factors make it so tricky to complete.
In the previous article, we established that digital images are based on numerical data. Computers are supposed to be good at processing numbers and doing math, so why is computer vision such a challenging problem that still faces low accuracy rates in many applications? It turns out there is some truth to the saying “a picture is worth a thousand words” - images have a lot of information density, because it’s not just about the underlying numbers but also the patterns that those numbers represent. The more numbers you have, the more patterns there could be, and the more possible meanings those patterns could have. There are a lot of pieces of information that we can extract out of an image, depending on the questions we might want to ask. Let’s explore this a bit more by referring to an example photo:

Your eyes perceive the image and send signals to your brain, which processes the patterns that it finds and refers to your memory and knowledge, allowing you to understand what is happening in this photo - all in less than a second! Now imagine that we have given this photo to a computer to process - what sorts of questions could we ask about this image?
We could ask “how many people are in the photo?”. This is already a complicated question, because we need to know what people look like. How would we describe the visual appearance of a person to a computer? We might say that people are somewhat rectangular and tend to be taller than they are wide, they tend to have two arms and two legs, they have patches of visible skin (although a lot is covered by clothing), and they have roughly oval faces made up of two eyes above a nose and a mouth. This is pretty broad, but we need a description of “people” that is generalisable, meaning that the definition is broad enough to cover all possible instances of people. The bodies of most of the people are partially obscured in the photo, and you can only see their faces - some faces are even partially blocked by other people as well, so our description of what people look like may have to be reduced to just a couple of facial features in order to detect everyone. This works until we realise that there’s even a person facing away from the camera - somehow our human brains know that this is a person, but how would we teach a computer to recognise that shape as being a person?

The description also contains a lot of keywords that need to be defined as well - for example, what defines a “nose”? These definitions have to be mathematical, looking for patterns across the numbers that make up the image. A lot of computer vision techniques look for edges, where the colour or brightness changes from light to dark or vice versa, indicating the boundaries of objects. The shape of those edges, combined with other measures of “texture” and “structure”, can give computers a pretty good idea of what objects they’re looking at. The above image shows some of the detected edges, and then those edges drawn on top of the original image in red. Just showing the edges loses a lot of detail for humans, but it reveals the underlying structure of the image and gives some indication of the shapes in the photo. It’s important to note that edges are just one of the features that computer vision algorithms look at. The image with the edges also shows something else important - the people in the back are a little blurry in the original photo, and the computer struggles to find the edges in the faces. While the human brain is pretty good at dealing with a little bit of blurriness, many algorithms do not perform as well. However, facial detection is one of the tasks in computer vision that is considered pretty close to solved these days - the latest algorithms using state-of-the-art deep learning can regularly achieve accuracy rates above 95% in uncontrolled environments.
Once we find all the people in the image, a natural follow-up might be “who is in this photo?”. Most of us would be able to take a quick glance at the photo and identify former US President Barack Obama, alongside his wife Michelle Obama. If you’re a political junkie, you might recognise former Speaker of the US House of Representatives John Boehner on the left, and there are a couple of other high-profile US politicians in the background. The human brain can be pretty quick at recognising people, commonly using facial features along with skin and hair. This is actually a skill that can be learned - looking at a lot of faces and matching them to names is something that can train your brain to perform better identification, literally rewiring the neurons and how they are connected inside your brain. The brain also reorganises memory to be efficient - people who you have seen recently or more frequently (like family members or celebrities) are easier and faster for your brain to retrieve and match, whereas other people (like old work colleagues or school friends from decades ago) sit in your long-term memory.

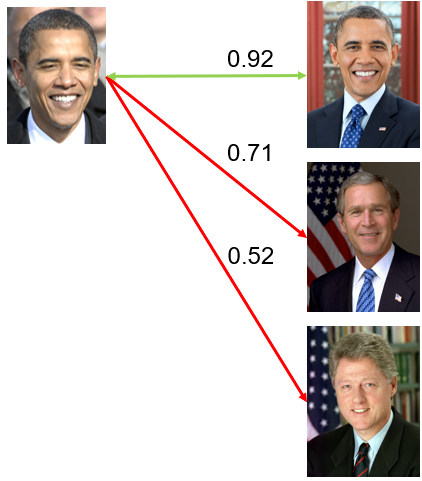
For a computer, identification requires that each person be reduced down to a numerical sequence that represents their appearance and structure. This could reflect the distances between the eyes and nose, or it could be more complex and capture characteristics like eye colour, nose shape, and cheekbone positioning. The computer then has to compare that sequence against a database of previously seen sequences (also known as templates), and try to find the closest match. Depending on the level of detail captured by that sequence, there could be a lot of potential for error - for example, if the sequence just represents a black hair colour and brown eyes, then there are plenty of people who would match that description. It also depends on who is in the database - if it is just a database of US politicians, then matching Barack Obama’s facial features might be relatively achievable, but if you have a database of every person in the US, then there is a higher likelihood that there is someone else who looks a little bit like Obama, and thus more of a chance for the algorithm to make a mistake. This is before we consider other aspects like ageing over time, the influence of lighting in the images, and the orientation of the faces. The facial recognition system being used by the UK police is reported to have an 81% error rate (although this depends on how you measure accuracy and error). Also, the bigger the database, the slower the matching process, because generally our target numerical sequence has to be checked against every sequence we already hold in the database. It’s a really long and difficult process, but it often seems simpler because computers are so good at math and can hide a lot of the complexity away.
Lastly, we might ask “why is this photo important?”. From the photo alone, this is almost impossible for a computer to figure out with current-day technology. A human looking at the photo would use context clues like Obama holding up his right hand, determining that the man facing away from the camera is wearing some form of robes (probably judge’s robes), that there are a lot of US politicians in the background, and so on. Many people (even those of us down here in New Zealand) would be able to quickly identify that this is from Obama’s inauguration or swearing-in ceremony, when he became the President of the United States. With more context clues like the approximate ages of the people in the background and the specific selection of the politicians in the background might help you identify that this is Obama’s first inauguration in 2009. If we are lucky, then the image might be captioned with some more details such as the specific date and the identities of other people (e.g. the person facing away from the camera is Chief Justice John Roberts), but this isn’t always available and if we really wanted to know more about the image and the context we would probably have to go look up some details. In theory, a computer should be able to do the same thing - it should be able to identify these context clues and gradually build a picture as it gets more and more detail, and search through the internet to find more information. But it’s still a really hard problem that requires knowledge, not just data. The human brain can connect the dots based on information adjacency - how contextually close pieces of information are to each other - but this is learnt over time and can be hard to teach a computer. It may take a genuinely intelligent Artificial Intelligence to be able to complete this task, not just narrow AIs that are good at one or two things.
By breaking down the visual tasks that our brains are completing, it exposes why computer vision is so challenging. A lot depends on the questions we are asking, but even the simple questions can be very difficult to answer mathematically and programmatically. The human brain is also extremely efficient, combining visual information with contextual knowledge in milliseconds, while computers might need seconds or minutes just to recognise a face. Computer vision has come a long way and achieved some amazing things over the last decade, but at the same time, computer vision still has a long way to go. Understanding human vision and how the brain processes the data from our eyes may give us the insights we need to develop better, smarter, and faster computer vision.
In the next article, we will look at some questions that you can ask to understand if a particular problem can be solved with computer vision, and where the bounds of the current technology are.
ElementX is an artificial intelligence agency on a mission to make AI more accessible. We specialise in language, vision and data to accelerate your business, streamline processes and uncover meaningful insights through data.


